TensorFlow的命令来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。TensorFlow是张量从图像的一端流动到另一端的计算过程,这也是TensorFlow的编程模型。
模型的运行机制
TensorFlow的运行机制属于’定义’与’运行’相分离。从操作层面可以抽象成两种:模型构建和模型运行。
| 名称 | 含义 |
|---|---|
| 张量(tensor) | 数据,即某一类型的多维数组 |
| 变量(Variable) | 常用语定义模型中的参数,是通过不断训练得到的值 |
| 占位符(placeholder) | 输入变量的载体,也可以理解成定义函数时的参数 |
| 图中的节点操作(operation, OP) | 即一个OP获得0个或者多个tensor,执行计算,输出额外的0个或者多个tensor |
关于’图’的理解:
- 一个’图’代表一个计算任务
- 在模型运行的环节中,’图’会在回话(session)里被启动。
- session将图的OP分发到如CPU或GPU之类的设备上,同时提供执行OP的方法。这些方法执行后,将产生的tensor返回。在python语言中,返回的tensor是numpy ndarray对象;在C和C++语言中,返回的tensor是TensorFlow::Tensor实例。
session与图的工作关系如下: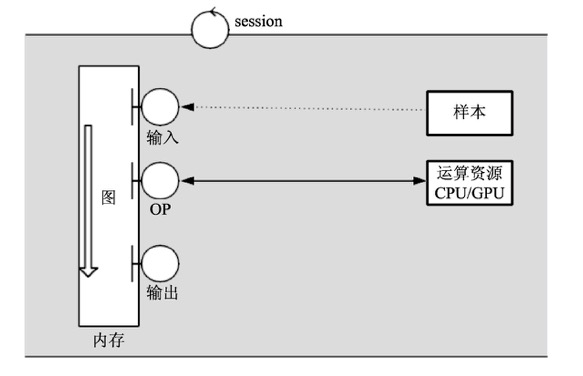
在实际环境中,这种运行情况会有3种应用场景,分别是训练场景、测试场景与使用场景。在训练场景下图的运行方式与其他两种不同,具体如下:
- 训练场景
实现模型从无到有的过程,通过样本的学习训练,调整学习参数,形成最终的模型。其过程是将给定的样本和标签作为输入节点,通过大量的循环迭代,将图中的正向运算(从输入的样本通过OP运算得到输出的方向)得到的输出值,再进行反向运算(从输出到输入的方向),以更新模型中的学习参数,最终使模型产生的正向结果最大化的接近样本标签。这样就得到了一个可以拟合样本规律的模型。 - 测试场景和使用场景
测试场景是利用图的正向运算得到的结果与真实值进行比较的差别;使用场景也是利用图的正向运算得到结果,并直接使用。所以二者的运算过程是一样的。对于该场景下的模型与正常编程用到的函数特别相似。在函数中,可以分为实参、形参、函数体与返回值。同样在模型中,实参就是输入的样本,形参就是占位符,运算过程就相当于函数体,得到的结果相当于返回值。
session与图的交互过程中定义了两种数据的流向机制:
- 注入机制(feed): 通过占位符向模式中传入数据
- 取回机制(fetch): 从模式中得到结果
session示例
|
|
计算两个变量(3和4)的相加与相乘值
占位符使用
建立session还有以下两种方式:
- 交互式session方式:一般在Jupyter环境下使用较多,具体用法与前面的with session类似
- 使用Supervisor方式:该方式会更高级一些,使用起来也更加复杂,可以自动来管理session中的具体任务,例如载入/栽出检查点文件、写入TensorBoard等,另外该方法还支持分布式训练的部署:1sess = tf.InteractiveSession()
保存和载入模型
保存模型
首先需要创建一个saver,然后再session中通过saver的save方法即可将模型保存起来:
载入模型
将模型保存以后,在session中通过saver.restore()函数来载入模型:
示例
|
|
运行完成后,在代码同级目录下log文件夹里生成了几个文件:
- checkpoint
- linermodel.cpkt.data-00000-of-00001
- linermodel.cpkt.index
- linermodel.cpkt.meta
把载入模型的代码块注释打开,就能从保存的模型成功载入,并计算出正确的值了。
获取模型内存
上面模型保存了,但仍然对我们不透明,如何知道保存了哪些东西?
保存模型的其他方法
- 指定变量名字与变量的对应关系1saver = tf.train.Saver({'weight': W, 'bias': b})
|
|
检查点(CheckPoint)
保存检查点
保存模型并不限于在训练之后,在训练之中也需要保存,因为TensorFlow训练模型时难免会出现中断的情况。我们自然希望能够将辛苦得到的中间参数保留下来,否则下次又要重新看似是。这种在训练中保存模型,习惯上称之为保存检查点。
如果觉得通过指定迭代次数比较麻烦,还有一个好方法可以快速获取到检查点文件:
还可以更简洁一些:
更简便的保存检查点
通过tf.train.MonitoredTrainingSession函数。该函数可以直接实现保存载入检查点模型的文件。这里按照训练时间来保存。通过指定save_checkpoint_secs参数的具体秒数,来设置没训练多久保存一次检查点。
将程序停止,可以看到log/checkpoints下面生成了监测点文件model.ckpt-73647.meta,再次运行程序可以看到程序自动载入检查点文件是从第72748次开始运行的。
TensorBoard可视化
TensorFlow还提供了一个可视化工具TensorBoard。它可以将训练过程中的各种绘制数据展示出来,包括标量(Scalars)、图片(Images)、音频(Audio)、计算图(Graph)、数据分布、直方图(Histograms)和嵌入式向量。可以通过网页来观察模型的结构和训练过程中各个参数变化。
当然,TensorBoard不会自动把代码展示出来,其实他是一个日志展示系统,需要在session中运算图时,将各种类型的数据汇总并输出到日志文件中。然后启动TensorBoard服务,TensorBoadr读取这些日志文件,并开启6006端口提供Web服务,让用可以在浏览器中查看数据。
可视化函数
TensorFlow提供了一系列API来生成这些数据:
| 函数 | 说明 |
|---|---|
| tf.summary.scalar(tags, values, collections=None, nameNone) | 标量数据汇总, 输出protobuf |
| tf.summary.histogram(tag, values, collections=None, name=None) | 记录变量var的直方图,输出带有直方图的汇总的protobuf |
| tf.summary.image(tag, tensor, max_images=3, collections=None, name=None) | 图像数据汇总,输出protobuf |
| tf.summary.merge(inputs, collections=None, name=None) | 合并所有的汇总日志 |
| tf.summary.FileWriter | 创建一个SummaryWriter |
| Class SummaryWriter: add_summary(), add_sessionlog(), add_event(), add_graphy() | 将protobuf写入文件的类 |
示例
|
|
然后到log目录下执行:
然后浏览器:localhost:6006 就能看到数据图
参考:<深度学习之TensorFlow: 入门、原理与进阶实战>